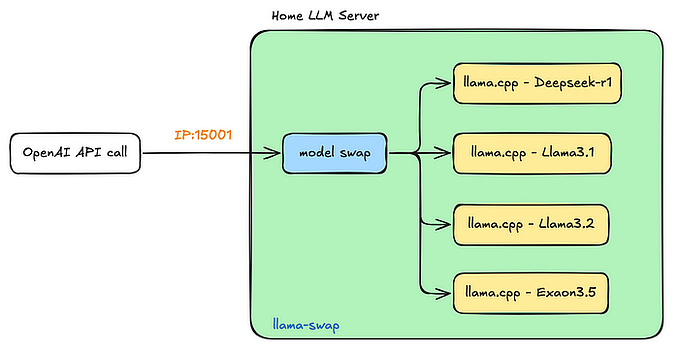
1.58 BitNet
This blog is written following the release of “The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits.” arXiv preprint arXiv:2402.17764 (2024). https://arxiv.org/abs/2402.17764, which has been seen as a significant improvement in quantization, and in memory reduction for LLMs. With the increasing size of models and data, it is becoming increasingly difficult to run and train these models for individuals and even for medium-sized groups without enough resources. This paper brings new possibilities for models that can do inference with significantly less memory. at the same time, performing at levels of actual FP16 models.
So, these are my explorations on this topic of Quantization and extreme quantizations such as these 1-bit/1.58-bit models and what they bring to democratizing LLMs.
Let’s start with Quantization, as it looks like the root concept behind this technique of reducing model memory.
Quantization
“Quantization is a technique to reduce the computational and memory costs of running inference by representing the weights and activations with low-precision data types like an 8-bit integer (int8) instead of the usual 32-bit floating point (float32).” — from Hugging-face, which has been my recent go-to place for ML concepts.
So, quantization is the processing of using lower bits to represent weights, like using int8 instead of actual float32.
The two most common quantization cases are float32 -> float16 and float32 -> int8.
Consider we have weights with float16
[[ 0.5, 1.2, -0.8] ,
[-1.0, 0.3, 0.7]]by quantization, we convert it to int8 values (all values are between -127 to 127 and integers)
[[ 64, 121, -102] ,
[-128, 38, 89]]The basic formula for this is shown as,
x_q = round(x/S + Z)
x: The original continuous variable that we want to quantize.
x_q: The quantized value of x.
S: The scaling factor. This parameter determines the size of the quantization bins. Larger values of S result in smaller quantization bins.
Z: The offset. This parameter determines the alignment of the quantization bins. It shifts the quantization boundaries.
You can check in detail @https://huggingface.co/docs/optimum/concept_guides/quantization and also this blog seems detailed https://towardsdatascience.com/introduction-to-weight-quantization-2494701b9c0c
Another thing to know is that not only the weights are quantized but also activations are quantized for some models.
There are a few types of quantization
- Post-training: In this, the model is initially pre-trained without any quantization. Then the pre-trained model is quantized during a separate quantization time or during the model runtime itself.
- Quantization-aware training: Here the models are quantized during the pre-training time itself.
This sums up a very naive intro to quantization, you can check for more quantization methods. In recent times, there have been many models for different types of quantization for all the transformer models.
BitNet
Now let’s see what are BitNets. In a way, it can be seen as an extreme case of quantization or Binarization. The main process is here the weights from full precision transformers such as float32 or float16 are quantized to binary values, i.e to [-1,1]
This model is brought my the paper “Bitnet: Scaling 1-bit transformers for large language models.” (2023). https://arxiv.org/abs/2310.11453.
1.58 BitNet
The main topic of this article is 1.58 BitNet. It is a model introduced following the steps of the BitNet model. Here instead of quantizing the weights to binary values[-1,1], they quantize them to ternary values [-1,0,1]. So, each weight can have values in [-1,0,1].
So why are they called 1.58 BitNet? instead of say TriNets.
This is from entropy, or in simpler terms number of values that can be represented in a variable.
for bits, each bit can represent two values 2.
- log base2(2) = 1, 1 bit can represent 2 values like [-1,1]
- log base2(4) = 2, 2 bits can represent 4 values like [0,1,2,3]
So, to represent 3 values,
- log base2(3) = 1.58496350072,i.e approximately 1.58 bits can represent 3 values like [-1,0,1]
so it’s called 1.58 BitNet.
Why ternary over binary?
58 BitNet has all the benefits of 1-bit BitNet. (reduces memory usage and computational computation complexity).
- It has explicit support for feature filtering, using the 0 for filters that are not useful. Am not exactly sure how this works, but the intuition is similar to Lasso Regression, which sets values of coefficient for features to be zero if not useful.
- It matches perplexity(i, how good a language model predicts the next word, lower the better) and end-task performance(can be other NLP tasks than LM) of full precision float16 models starting from 3B size.
So let’s say it just performs better using ternary instead of binary weights.
Now that we understand the naming and what the model quantizations are, let’s try to understand the math behind it.
Math
As discussed earlier, quantization can be done only for weights, or for both weights and activation values. Both BitNet and 1.58 BitNet do quantization for weights and activations
BitNet
BitNet uses low-precision binary weights and quantized activations to 8 bits, and high-precision for optimizer states and gradient functions during training. It can be represented as a “w2a8” quantized model.
for weights,
The weights are binarized to either +1 or -1. The weights are first centralized to have a mean of zero. Then we use a signum() function, which converts positive values to 1, and negative and zero to -1.
def signum(weight):
if weight>0: return 1
else: return -1
def QuantWeight(W):
#Let W be the weights and W_q quantized weights
alpha = mean(W)
for weight in x:
weight = W-alpha
weight = signnum(weight)
W_q.append(weight)
return W_q
for activation,
Activations are quantized to b-bit precision(8-bit for bitnet) using absmax quantization. Scales activation into range[-Q_b, Q_b], where Q_b = 2^(b-1). b=8, so it scales to [-128,128].
# clips x between range [a,b], a is min clip value and b is max clip value
# for example, Clip(-5,0,10) = 0 and Clip(57,0,10) = 10
def Clip(x,a,b):
max(a,min(b,x))
b = 8 #Bitnet uses 8-bit precision for quantization
#quantizes X using absmax quantization
def QuantX(X):
gamma = max[abs(num) for num in X] #finding absolute maximum from weights
Q_b = 2^(b-1) # this is scaling range [-Q_b,Q_b]
X_q = []
for x in X:
X_q.append(clip(x*Q_b/gamma,-Q_b,Q_b))
return X_qFor activations before non-linear functions, it is scaled to [0, Q_b]. buy subtracting each value with min value in inputs.
def QuantX(X):
gamma = max[abs(num) for num in X] #finding absolute maximum from weights
min = min(X)
Q_b = 2^(b-1) # this is scaling range [-Q_b,Q_b]
X_b = []
for x in X:
X_b.append(clip((x-min)*Q_b/gamma,0,Q_b))
return X_qTo prevent floating point overflow a small number is added to ranges.
So now we have W_q, and X_q quantized. One missed step is Layer Normalisation, it is said we layer normalize the inputs before quantizing them to maintain variance, (which is required for good model initialization and helps in training stability).
Finally, we have to dequantize the result y = W_b * X_b. It is done by rescaling with {Beta, min}. Beta is the absolute mean of the weights, unlike alpha which is the mean weight.
def BitLinear(W,X):
W_q = QuantWeight(W) # quantizes weight W into binary values [-1,1]
X_q = QuantX(X) # quantized inputs to 8-bit precision
y = W_q . X_q
beta = mean[abs(num) for num in W] #mean of absolute weight
Q_b = 2^(b-1)
return y * beta/Q_b #dequantised by rescaling with {beta, Q_b}In BitNet, we use this BitLinear block for quantizing the weights, and activations performing the multiplication operations and de-quantizing the results.

This image represents the flow of data in the BitLinear block better. This operation is performed in groups of weights and activations for parallelism.
1.58 BitNet
1.58 BitNet uses low-precision binary weights and quantized activations to 8 bits, and high-precision for optimizer states and gradient functions during training. It can be represented as a w1.58a8 quantized model I guess.
for weights,
Weights are quantized to ternary values [-1,0,1]. It scales the weight matrix similar to bitnet first, by average absolute value(beta in BitNet), and then rounds each value to the nearest integer among [-1,0,1]
def RoundClip(x,a,b):
max(a,min(b,round(x))
def Quant(W):
gamma = mean[abs(num) for num in W] #mean of absolute weight
W_q = []
for w in W:
W_q.append(RoundClip(w/gamma,-1,1))
return W_qfor activation it uses the same as BitNet, except for non-linear function it still scales to [-Q_b, Q_b]
All other parts are assumed to be the same as BitNet, as details are not mentioned in this paper.
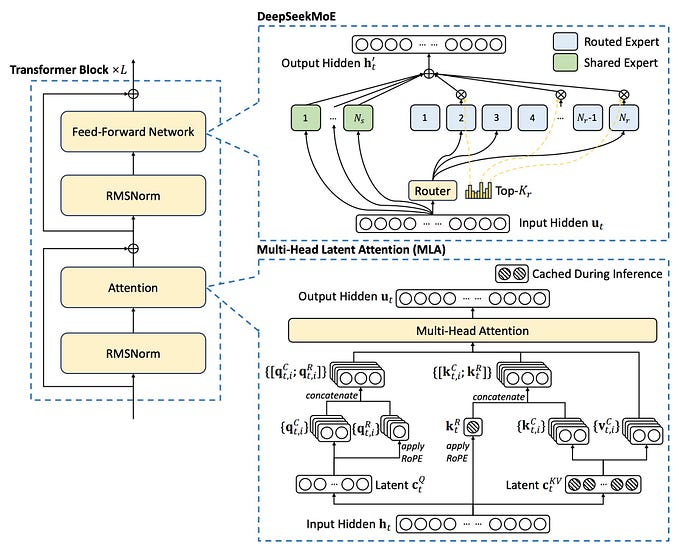
Model Architecture
Below shown is the architecture of BitNet, a similar one is assumed for 1.58-BitNet with changes in BitLinear(for quantizing weights to ternary instead of binary values). As we can it uses transformer blocks, where it uses BitLinear block instead of conventional matrix multiplication. Quantization is not done for residual connections and QKV transformation, as its effects are negligible and their computation cost is smaller as the model grows. Also not done for the input and output of transformer blocks, as language models have to use probabilities to perform sampling. (Which means they require FP precision).
1.58 BitNet model is said to be based on the LLaMA model, so we can assume it’s LLaMA with these components replaced in transformer blocks of it.

Model Training
Straight-through estimator
It uses the straight-through estimator to approximate gradients for non-differentiable functions like clip() and signnum(), during backpropagation, making it possible to train the quantized models.
Mixed Precision training
Gradients and optimizer states are stored in high precision to ensure training stability and accuracy. It is quantized during the forward pass and used only during backpropagation. It’s not used in inference, only quantized weights are used during inference.
Large learning rate
From experiments they suggest using larger learning rates helps in convergence.
Comparisons
from paper to FP16 transformers and other quantizations
- Unlike vanilla transformers, for Bitnet and 1.58 Bitnet, the matrix multiplication operations are major additions of 1-bit or ternary values. It significantly reduces the energy consumption during forward pass in training and inference.
- Scaling law: Previous scaling laws used relationships between loss and actual computing. But it doesn’t help for Bitnets, as it’s more integer computation and not FLOPS. So, in the bitnet paper, they use an Inference-Optimal Scaling Law showing the relationship between loss and energy consumed.


You can the energy consumption comparison between BitNet models and FP16 transformers. We can see in the first graph from BitNet paper, that energy consumption is much less than FP16 transformer, while the loss becomes almost as less as FP16 at 100B. The second row of graphs below shows 1.58 BitNet energy consumption data against LLaMA which it is based on.
You can see the further comparisons in performance for downstream tasks in the paper experiment section. Overall, it shows that the 1.58 BitNet model is performing at par with full precision LLaMA 3B models, at very reduced memory and reduced computations.
Future areas to explore(from paper)
MoE
The mixture of expert models is another kind of transformer-based model, where the FNN part of transformers is replaced with a mixture of experts, controlled by a Routing/Gating unit. It by itself reduces computation FLOPs, but brings in high memory consumption challenges, as it has more models/experts in its memory(model parameters), even though only one will be used for computation. Using something like BitNet can help with reducing this memory dependence further enhancing its capabilities. You can check further details about MoE at @https://huggingface.co/blog/moe.

Long sequence
The paper suggests that reducing memory consumption can increase the LLM context length, which is desirable for LMs. Quantizing activations to 8 bits allows the context length to be doubled. Further quantizing the activations to lower precisions, can increase the context length further.
Edge LLM
With less memory dependency we can run LLMs on edge/mobile systems which have comparitively less memory onboard.
New Hardware? Groq?
Maybe there will be specialised processing units developed for 1-bit LLMS, similar to how we have LPU (Language processing units) developed specifically to cater for LLM models by Groq.
There are so far my explorations with the papers below and am planning to further try this method and wait for more details on the 1.58 model from Microsoft. Please feel free to correct me if there is something wrong or any inaccuracies, as I am new to these LLMs in general.
References:
- Ma, Shuming, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. “The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits.” arXiv preprint arXiv:2402.17764 (2024). https://arxiv.org/abs/2402.17764
- Wang, Hongyu, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. “Bitnet: Scaling 1-bit transformers for large language models.” arXiv preprint arXiv:2310.11453 (2023). https://arxiv.org/abs/2310.11453
- Quantization -https://huggingface.co/docs/optimum/concept_guides/quantization